
Exploring GPT-4 Vision Use Cases
What happens if an AI has eyes?


Hello everyone!
One by one, the AI community is building the parts for our Frankenstein Founder…
Follow me on X if you want to stay updated with my latest ramblings.
In this post, I look at existing applications leveraging GPT4-V, a framework to understand AI vision capabilities, unpacking what is holding back use cases, and what future opportunities may be around the corner.
One intriguing observation to kick things off: interest in GPT4-V, as indicated by search trends, appears to be waning. Why is that? I think people are massively underestimating AI vision right now. My takeaway after exploring this topic is that the applications of AI vision are going to feel like they came out of nowhere all at once. Let’s dig in!

What is it?
GPT4-V is OpenAI’s multi-modal AI that combines natural language processing capabilities with computer vision. Currently, it is available directly in ChatGPT Plus and OpenAI API.
GPT-4 does not support fine-tuning for image capabilities; however, DALL-E 3 is available for generating images, and GPT-4-Vision-Preview can be used to understand images.
As a more practical explanation, I asked GPT4 to summarize what type of images it can interpret. Below are the answers:
Photographs: It can recognize and interpret various elements within photographs, including landscapes, urban scenes, people, animals, objects, and activities.
Artworks: It can understand and analyze different art styles and periods, from classical paintings to modern digital creations. However, it adheres to specific policies regarding contemporary and copyrighted art.
Graphs and Charts: It can interpret data visualizations, including bar graphs, line charts, pie charts, and scatter plots, helping to explain the data or trends represented.
Diagrams and Schematics: It can understand various diagrams and schematics, such as technical drawings, flowcharts, and maps, providing insights into their structure or meaning.
Text in Images: It can recognize and interpret text within images, which enables it to provide context or additional information based on the text content.
Symbols and Icons: It can identify and explain the meaning of various symbols, signs, and icons found in images.
GPT-4 Vision can analyze these images to extract information, understand context, recognize objects and their attributes, and even make inferences based on the visual content. This capability allows for a broad application in fields such as art analysis, data interpretation, educational assistance, and more.
Top 5 AI vision use cases
1. Sketch-to-Code Generation - @tldraw is leading the way with code generation from a whiteboard canvas. In my opinion, this is the best-executed use case for AI Vision so far!

Not only is it possible to generate code for the UI, but you can also leverage the whiteboard tools to code logic.

2. Image and Video Narration
If you have not seen it yet, Charlie Holtz made a hilarious demo featuring David Attenborough's voiceover from real-time webcam snapshots. Gonzalo Graham used GPT-4V + TTS to create an AI sports narrator.

3. Data interpretation
The model can interpret various forms of data, for example:
Images
Maps
Charts
Graphs
Sketches
I'm intrigued by the possibility of uploading screenshots from platforms like Stripe, Google Analytics, Mercury, Segment, etc. and utilizing GPT4 Vision for data cleanup and interpretation. If you're aware of any examples or demos, please share!
4. Object identification and tracking
I made a demo video using GPT-4 Vision to “catch real-life Pokemon”.
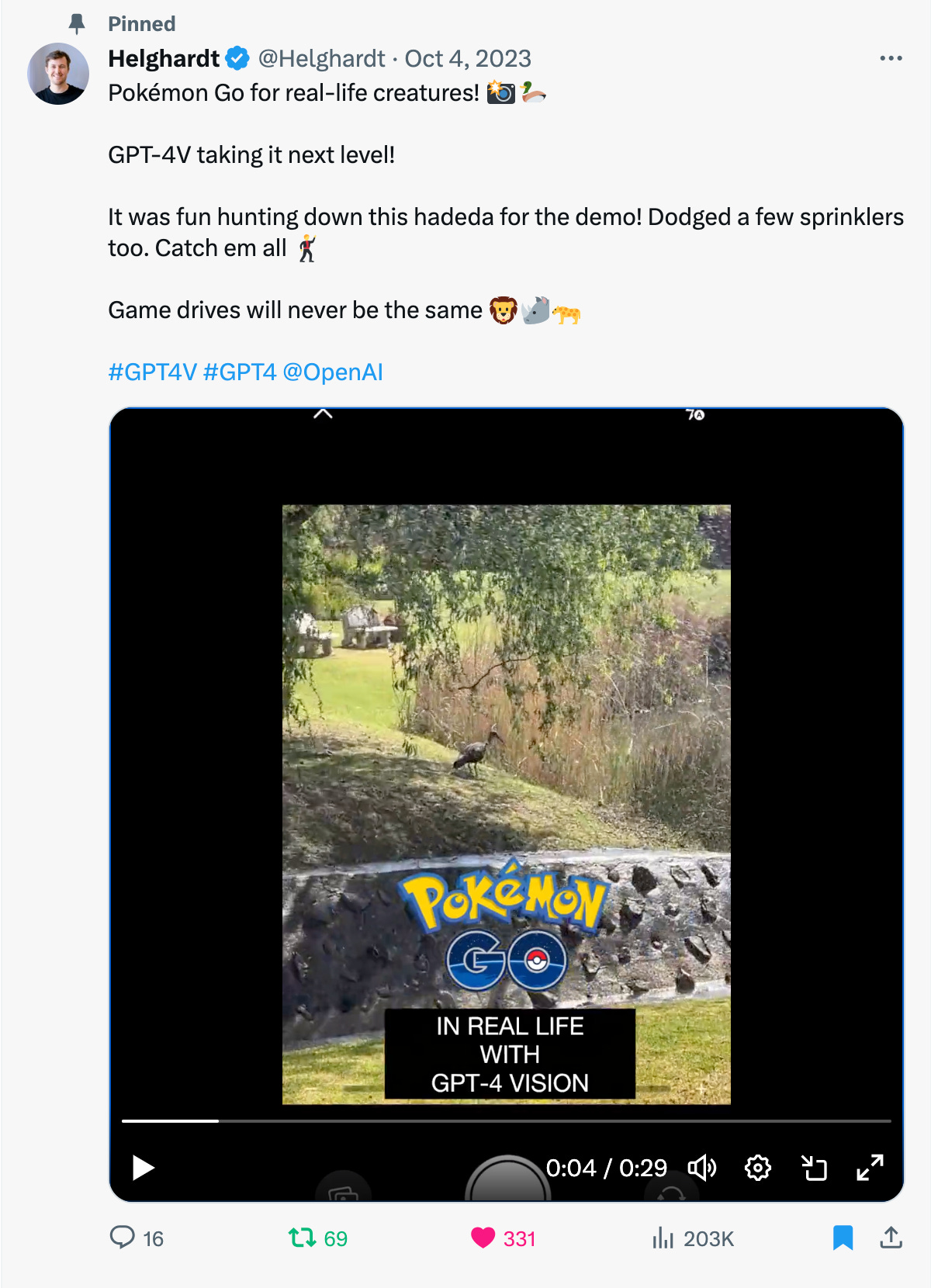
Similarly, AI Vision can be used to identify and track specific objects, whether it is to count livestock, inventory management, traffic on key intersections, etc. In the example below I asked ChatGPT to count the number of buffalo in the picture:

5. Robotics and real-time training
Before GPT-4 Vision the majority of AI use cases have been limited to digital-only interpretation and action. In the example below I asked GPT to determine the coordinates of the buttons on an ATM keypad. Now imagine being able to provide such context to a real-world robot!

A particularly noteworthy study, Robotic Vision-Language Planning (ViLa), showcases an innovative integration of vision-language models (VLMs) with robotic planning. This research marries the depth of reasoning and planning found in large language models with a tangible understanding of real-world contexts. By incorporating real-world perceptual data, ViLa enables robots to navigate and manipulate their environment, reflecting a leap in our ability to harness AI for complex, open-world tasks.

A framework to understand AI vision capabilities
I find it useful to understand at least some of the layers in a new technology to better identify possible use cases. GPT 4 Vision has made massive advancements in each of these aspects as a multi-modal AI model.
Identification and Object Recognition - This is the foundational capability of AI vision, where the system identifies objects, people, scenes, or activities within visual content. Opportunities in this domain are vast, ranging from retail (e.g., product recognition for inventory management) to security (e.g., surveillance monitoring).
Analysis and Contextual Understanding - After identification, GPT-4V can analyze the context and details of the visual content. This involves understanding relationships, patterns, or changes over time within the data. For instance, analyzing traffic patterns from drone footage for urban planning or assessing crop health in agriculture from satellite images.
Interpretation and Decision Making - This stage involves synthesizing the analysis to derive meaningful conclusions or insights. In healthcare, for example, interpreting medical images to assist in diagnosis; in sports, analyzing players' movements to enhance performance strategies.
Feedback Loops and Adaptive Learning - Incorporating a feedback loop allows the system to learn and adapt from its interpretations, enhancing the accuracy and relevance of the insights over time. This could be particularly useful in dynamic environments such as financial markets for real-time trading insights or interactive educational tools that adapt to a student's learning pace.
Action and Autonomous Systems - The ultimate goal is for AI not just to analyze and interpret data but also to act upon those insights. This could manifest in autonomous decision-making, such as AI-driven drones responding to environmental changes, or training a robot arm to iron clothing.
What is holding back AI Vision use cases?
I asked ChatGPT to help me explore this question and distilled my conversation into 6 points:
Data Privacy and Ethical Concerns - Even though GPT4 can already offer a lot of value, privacy, and ethical concerns are major hurdles we still need to cross. As an example of what the AI can do, Javier Alvarez-Valle and Matthew Lungren explored GPT-4's capabilities in radiology, demonstrating its potential to improve disease classification, findings summarization, and report structuring. Their study indicates GPT-4 can match and sometimes surpass experienced radiologists in generating radiology report summaries.

GPT 4 results from the report. Technical Limitations and Accuracy - AI Vision's reliability and accuracy issues limit its adoption in unpredictable environments. For example, a mining company using AI Vision to determine machinery maintenance needs faces challenges due to poor lighting, dust, and unique wear patterns, which can hinder the AI's ability to make accurate assessments.
Lack of Standardization and Integration - Businesses ready to benefit from AI Vision often have established systems, making integrating new AI technologies a low priority without clear benefits. For example, a retail chain might hesitate to adopt AI Vision for inventory management due to the complexities and costs of modifying their existing setup, highlighting the challenges of integrating AI Vision into current systems without standardized, easy-to-adopt solutions.
Strategic Timing for Technological Adoption - Businesses frequently opt to defer the adoption of existing AI vision technologies, holding out for future, more sophisticated iterations. This approach minimizes the financial and logistical challenges of updating systems.
Skill Gap and Training Requirements - The effective use of AI vision technologies requires a workforce skilled in both the technology and its application in specific industries. The significant skill gap presents a barrier to AI vision's adoption, necessitating comprehensive training programs to equip employees with the necessary expertise. This is particularly evident in healthcare, where staff needs to be trained not only in using AI technology but also in accurately interpreting its outputs for diagnostics.
Complex Reasoning Limitations - AI vision is not yet performing optimally when it comes to visual interpretation and complex reasoning. For example, Akruti pointed out in his blog post that when tasked with solving an easy-level New York Times Sudoku puzzle, it misinterprets the puzzle question and consequently provides incorrect results.


Vision AI future opportunities
As a fun exercise, I looked at 7 industries and tried to come up with 1 or 2 ideas for each industry using AI vision in some form or another.
1. Retail and E-commerce
Brand Trend Analysis: Utilize AI vision to monitor social media platforms, analyzing images and videos to track brand visibility and sentiment trends. This can help retailers adjust marketing strategies in real-time. The below example can quickly pick up on the brands Dricus is wearing where it is visible, e.g. Polo.

Visual Search and Recommendation: Enhance the shopping experience by allowing customers to upload images of items they like, using AI to find similar products in the store's inventory, facilitating personalized recommendations.
2. Finance
Receipt and Invoice Processing: Streamline expense management by scanning receipts and invoices, extracting detailed information for financial analysis and budgeting with greater accuracy and efficiency.
Stock Chart Interpretation: Offer investors the ability to upload stock chart images, providing AI-powered analysis to decode patterns, trends, and potential investment insights. This Hackernoon post featured an example of a financial analyst as seen in the screenshots below.
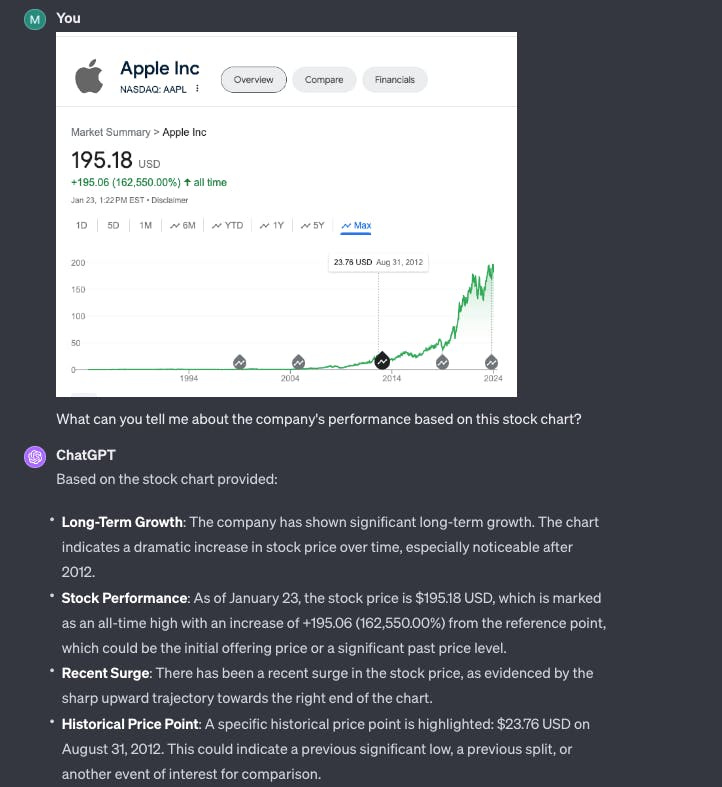
3. Mining
Equipment Inspection: Use AI vision for remote monitoring and inspection of mining equipment, identifying signs of wear, damage, or the need for maintenance, enhancing safety and operational efficiency. The below example evaluates the wear on the tires of a mining truck.


4. Travel and Dining
Custom Itinerary Generation: Allows travelers to upload maps or destination photos, and AI creates personalized travel itineraries with routes, attractions, and dining options based on visual cues and preferences.
Food Quality Inspection: Equip restaurants with AI vision to analyze dishes before serving, ensuring presentation and quality meet standards, enhancing customer satisfaction.
5. Sports and Fitness
Posture and Form Feedback: Provide athletes and fitness enthusiasts with instant feedback on their posture and form during exercises, using AI vision to compare against optimal techniques for injury prevention and performance improvement.
Golf Swing Analysis: Offer golfers a detailed analysis of their swing through video uploads, giving improvement tips based on comparisons with professional standards. The below example provides useful feedback on the tee setup of a golfer:
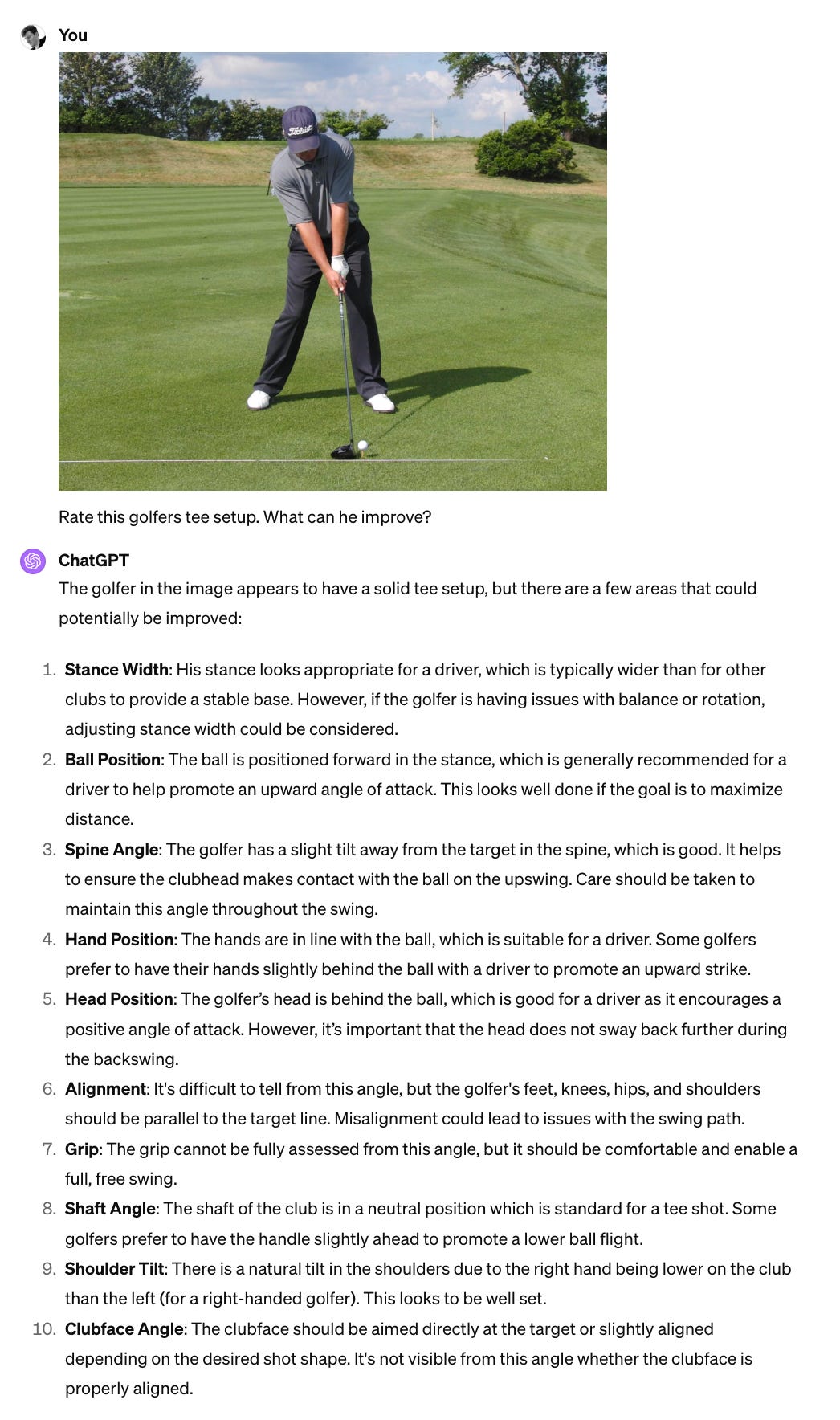
6. Healthcare
Skin Health Monitoring: Empower individuals to track changes in their skin over time, using AI vision to detect early signs of conditions like melanoma, encouraging timely medical consultation.
Enhanced Radiology Analysis: Support radiologists by automating the initial review of scans, highlighting areas of interest to streamline the diagnostic process and improve accuracy.
7. Environment, Nature, and Wildlife
Recycling Guidance: Assist users in sorting waste by analyzing images of items, determining if they are recyclable, and providing guidance on proper disposal methods. Below I asked ChatGPT to identify the objects that can/can’t be recycled:

Here is the downloaded image:


Astronomical Exploration: Enhance stargazing experiences by identifying celestial bodies and constellations in real-time through a smartphone camera, making astronomy more accessible and informative.
Wildlife Age Estimation: Aid wildlife conservation efforts by estimating the age of animals through visual analysis, supporting better wildlife management and care practices.
What does this mean for AI-starting startups?
AI vision is opening new use cases in almost all industries that were not previously possible. It moves the needle significantly in making it even more viable for AI to start and run a startup - in particular introducing real-time, real-world context! Whether this is applied to analyze data for decision-making, training robot models, monitoring human performance, evaluating environmental conditions, etc, the AI can now see!
Conclusion
The power of GPT-4 Vision is mind-blowing and is currently best demonstrated by @tldraw’s sketch-to-code generator. Secondly, I think the impact of AI vision in training robots to interpret the real world is particularly exciting!
My main conclusion is that AI vision is ready for many use cases, but the use cases aren’t ready for AI vision. AI vision is akin to the Wright Brother’s first flight at Kitty Hawk. The limitations are of the kind that tends to be slow to break through; it will happen steadily and then all at once!
It can not be ignored that by giving AI real-world context we are edging closer to a world where AI starts and runs a business!
Incredible, loved this topic choice!